Dağıtık Uygulamada Büyük Veri Okumak
2020 senesi içerisinde Inomera‘da Telekom sektörü için geliştirdiğimiz devasa bir projeyi başarıyla canlıya aldık. Oldukça güncel teknolojiler kullandığımız ve mikroservis mimarisi ile geliştirdiğimiz bu sistem Kubernetes ortamı üzerinde çalışmakta. Bu yazıda bu sistemde yaklaşık 22 milyon satır kullanıcı verisini veritabanından okuyup dağıtık bir cache Map’ine dolduran küçük bir mikroserviste uyguladığımız dağıtık veri okuma yöntemini anlatmaya çalışacağım.
Önbilgi
Öncelikle kullandığımız araçlardan ve veri yapısından bahsedelim.
-
Belleğe doldurmaya çalıştığımız veri her bir msisdn, yani müşterinin cep telefonu numarası, için müşterinin izin verdiği kategorilerin ID’lerinden oluşmakta olup Oracle DB üzerinde başka sistemler tarafından yönetilen bir view’dan bize sağlanmakta. Burada işin içinde çok fazla farklı müşteri sistemi olduğu için daha performanslı bir veritabanı veya tablo yapısına geçemiyoruz.
-
Veriyi belleğe çeken uygulamamız kubernetes üzerinde çalışmakta. Dinamik olarak kaynak ihtiyacına göre Kubernetes tarafından instance sayısı arttırılıp azaltılabilmekte bu sebeple herhangi bir anda uygulamamızdan kaç adet instance’ın eş zamanlı çalışıyor olabileceği bilgisi elimizde yok. Kubernetes API’lerini kullanarak bu bilgiyi elde edebilecek olsak da uygulamanın içerisinde Kubernetes bağımlılığı oluşturmak istemedik.
-
Dağıtık cache olarak Kubernetes dışında kurulmuş bir Hazelcast cluster’ımız var. Herhangi bir müşterinin verisine herhangi bir mikroservisten çok hızlı bir şekilde ulaşabilmek için Hazelcast üzerindeki bir Map’de tutuyoruz. Hazelcast’in ayrıca bu işte Queue ve Lock özelliklerini de kullandık.
Bu boyutta bir veriyi hızlı bir şekilde az bellek kullanarak sorgulayıp, işleyip, Hazelcast’e doldurmak için uygun bir yol ararken bu yazıda anlatacağım yöntemin ihtiyacımızı karşılayacağını öngördük.
Bellek Kullanımı
Bir veritabanına büyük bir veri için sorgu atılacağı zaman düşünülmesi gereken en önemli şeylerden birisi veritabanından sonuçlar geldiği zaman uygulamanın bellek tüketiminin nasıl artacağıdır.
Eğer veriyi işlemeye başlamak için verinin tamamına ihtiyacımız yoksa, verileri parça parça alıp, aldıkça işlemeliyiz.
Bunun için en bilindik yöntemlerden birisi offset/limit sorgusunu offset’i arttırarak tekrar tekrar atarak sayfalama (pagination) yapmak fakat bu yöntem her seferinde veritabanına yeniden sorgu atmayı gerektirdiği için faydasından çok zararı oluyor.
Verileri parça parça çekmek ve işledikçe devamını okumak için Hibernate’deki scroll özelliğini kullandık.
Sorgunun envai çeşit hibernate kontrolünden ve transaction yönetiminden geçmemesi için
Hibernate’deki StatelessSession sınıfı üzerinden sorgumuzu read-only modda attık.
Ek olarak bir ORM aracı ile sorgu sonuçlarının otomatik olarak entity sınıfına çevirilmesi özelliğinden de çok fazla reflection ve nesne kullanımının olmaması için feragat ediyoruz. Garbage Collector ve CPU biraz rahatlamış oluyor bu sayede.
Hibernate’de bu şekilde bir sorgu nasıl atılır aşağıda ufak bir örnek paylaşıyorum.
Buradaki fetchSize parametresi veritabanından sonuçların kaçar kaçar belleğe alınacağını belirliyor.
public void fetchMsisdnCategories(QueryState queryState, int fetchSize, Consumer<MsisdnCategoriesRecord> processor) {
try (final StatelessSession statelessSession = sessionFactory.openStatelessSession()) {
final String nativeSql = buildNativeSql(queryState);
final NativeQuery query = statelessSession.createNativeQuery(nativeSql);
query.setFetchSize(fetchSize);
query.setReadOnly(true);
final ScrollableResults scrollableResults = nativeQuery.scroll(ScrollMode.FORWARD_ONLY);
while (scrollableResults.next()) {
final Object[] rawRowData = scrollableResults.get();
final Long msisdn = Long.valueOf((String) rawRowData[0]);
final byte[] categoryIds = parseCategoryIdsAsByteArray(rawRowData[1]);
/* Caller processes the result in `rawRowData` */
processor.apply(new MsisdnCategoriesRecord(msisdn, categoryIds));
}
}
}
Bu method içerisinde çektiğimiz her satırı hemen sonuçları işleyecek olan Consumer sınıfına gönderiyoruz.
Böylece herhangi bir şekilde uygulamanın belleğinde aşırı birikme yaratmamış oluyoruz.
Yukarıdaki methodu çağıran sınıf Consumer arayüzünden oluşturulmuş bir sınıfı parametre olarak gönderiyor.
Yani DAO katmanından çıkacak olan her bir MsisdnCategoriesRecord nesnesinin nasıl işleneceğini DAO katmanına
yazmamış oluyoruz.
DAO katmanındaki methodumuzu çağıran servis katmanı ise gelen her bir sonucu doğrudan Hazelcast’e atıyor.
private final MsisdnCategoriesDao msisdnCategoriesDao;
// Hazelcast Map
private final IMap<Long, byte[]> msisdnCategoriesMap;
public void reloadMsisdnCategories(QueryState queryState) {
msisdnCategoriesDao.fetchMsisdnCategories(queryState, fetchSize, (record) -> {
msisdnCategoriesMap.put(record.getMsisdn(), record.getCategoryIds());
});
}
Sorgunun Dağıtılması
Yukarıdaki kod ile bir uygulama instance’ı tek başına DB’deki tüm datayı çekip Hazelcast Map’ine atabilir değil mi? Peki birden fazla uygulama instance’ı ayakta olduğu durumda datayı nasıl dağıtıyoruz?
Açık konuşmam gerekirse çözüm bulmakta en çok zorlandığımız kısım burası oldu. Bir öğle yemeğinde tartışırken aklımıza gelen şu çözümü beğendik ve o günden beri kullanıyoruz.
Öncelikle atılacak sorguları modüler aritmetik kullanarak parçalara bölüyoruz. Cep telefon numarası 905XXXXXXXXX formatında 12 adet rakamdan oluşan bir sayı olduğu için modüler aritmetik işlemlerinde msisdn alanını tercih ettik.
Sorgumuzdaki WHERE cümleciğinde ise şu şekilde modüler aritmetik koşuluna yer verdik:
select
/*+ parallel(%s) */
MSISDN,
listagg(CATEGORY_ID, ',') within group(order by MSISDN) CATEGORY_IDS
from VIEW_MSISDN_CATEGORIES
where
MSISDN is not null and
CATEGORY_ID is not null and
MOD(MSISDN, %s) = %s
group by MSISDN
Yukarıdaki reloadMsisdnCategories ve fetchMsisdnCategories isimli methodlarda belki dikkatinizi çekmiştir
QueryState isminde bir sınıf kullanıyoruz sorguları oluştururken.
Bu sınıf atılacak olan sorgunun hangi modda hangi kalana göre atılacağı bilgisini taşıyor.
public class QueryState implements Serializable {
private static final long serialVersionUID = 1L;
private final int mod;
private final int remainder;
public QueryState(int mod, int remainder) {
this.mod = mod;
this.remainder = remainder;
}
}
Böylece mikroservisimizin her bir instance’ının belli bir QueryState için sorgu atmasını sağlayabilirsek problem çözülmüş olacaktı.
Peki o anda mikroservisimizden kaç instance ayakta bilgisini bilmeden nasıl tüm instance’lara görev dağıtabiliriz? Bu noktada zorlandığımız nokta şuydu, instance sayısı kadar mod almaya çalışıyorduk. Hiçbir instance’ın boş yatmaması için tüm instance’ların işin bir ucundan tutması gerekiyordu. Çözümü bulduğumuz gün bunun için instance sayısını bilmeye ihtiyacımız olmadığını keşfettik.
Aşağıdaki diagramda olduğu gibi, tüm DB’yi okuyup veriyi belleğe yükleme görevini alan mikroservis,
belirli bir mod değerine karar verip, bir hazelcast queue’suna mod sayısı kadar QueryState nesnesini
farklı kalan değerleri ile dolduruyor. Tüm mikroservis instance’ları hali hazırda açık duran
birer Thread ile bu belirli Queue’dan gelecek olan mesajları dinlemekteler.
Her instance Queue’dan kendine düşen QueryState nesnesindeki mod ve kalan bilgisine göre sorgusunu atıyor
ve veritabanından gelen sonuçları Hazelcast Map’ine dolduruyor.
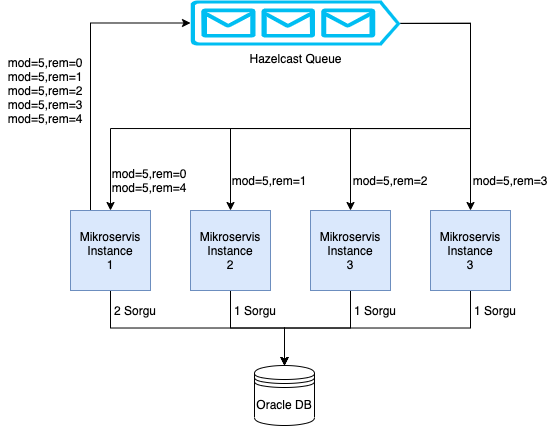
Burada queue’ya attığımız QueryState nesnelerinin sayısı (ya da mod değerimiz) instance sayısına tam bölünmüyorsa
bazı instance’lar diğerlerinden daha fazla sorgu atabilirler veritabanına.
Eğer mod değerimiz instance sayısından küçük ise bazı instance’larımız hiç sorgu atmayabilirler.
Biz mikroservisin instance sayısının alabileceği maksimum değer civarında
bir sayıyı mod değeri olarak kullanıyoruz
ve bu değeri runtime’da değiştirebileceğimiz konfigüratif bir yapıda tutuyoruz.
Ufak İyileştirmeler
Tüm mikroservislerin işi belli ölçülerde paylaşıp üzerlerine düşen görevi yaptıklarından emin olduktan sonra artık her bir mikroservisin elindeki işi yaparken daha performanslı çalışması için ne yapabiliriz bunu düşünmenin zamanı geldi.
Bu tip uygulamalarda en büyük zaman kaybı genellikle IO (network veya disk) kaynaklı olur. Veritabanından veriyi okuma kısmındaki git-gel işlemlerini sorguları scroll özelliğiyle atarak oldukça azalttık. Geriye hazelcast’e verileri gönderdiğimiz yer kalıyor. Hazelcast aracını da uygulamadan ayrı bir cluster şeklinde kurduğumuz için hazelcast operasyonları da network işlemlerinin büyük çoğunluğunu oluşturmakta.
DAO katmanından gelen her bir satır için hazelcast’e bir .put işlemi çağırmak yerine öncelikle
gelen satırları küçük gruplar halinde (1000 adet gibi) toparlayıp sonrasında .putAll methodunu çağırarak
tek seferde network’e çıkarak küçük bir iyileştirme sağlayabildik. Burada önemli nokta elimizdeki verinin
karakteristiğine göre memory üzerinde fazla birikme oluşturmayacak doğru sayıyı seçmek.
Sonraki aşamada hazelcast dökümantasyonlarını karıştırırken bildiğimiz java Map’lerinde olmayan
.set ve .setAll isimli methodlarının Hazelcast’in IMap arayüzünde bulunduğunu fark ettik.
put* türevi methodlar veriyi hazelcast’e koyduktan sonra Map’de ilgili key’e ait varolan eski veriyi dönerken
set* türevi methodlar herhangi bir şey dönmüyorlar.
Bu methodları kullandığımız durumda network katmanını kullanmayacağımız bir veri için boşuna meşgul etmemiş oluyoruz.
Sonuç
Bu yazıda anlattığım yöntemleri kullanarak tek bir instance’da çalışan, tüm veriyi veritabanından hazelcast’e doldurması bir saati bulan bir görevi 10 dakikanın altında çalışır hale getirdik. Sorgu attığımız veritabanı yapısında değişiklik yapma şansımız olsaydı daha iyi süreler de elde edebilirdik fakat o yapıyı bizden başka birçok farklı sistem kullandığından öyle bir şansımız malesef bulunmamakta.
Özetlemek gerekirse bu tip bir görev için kullanmaktan çok keyif aldığım şu teknikleri uyguladık:
- Modüler aritmetik kullanarak sorguları dağıtma
- Bilinen ORM yapısından çıkıp daha native tarafa yakın sorgular kullanmak
- Veritabanı sorgusunun sonuçlarını scroll ederek okumak
- Aynı uygulamanın birbirini görmeyen/bilmeyen instance’ları arasında görev dağılımı
- Verinin bellekte minimum yer kaplayacak formatta tutulması
Bu yöntemlerin bu yazıda gösterdiklerimden çok fazla sayıda farklı implementasyonları vardır fakat büyük işlerde önemli olan yöntemlerdir. Araçlar değişir.
Bu yazı 2020 Ağustos ayında başladığım fakat bir türlü vakit ayırıp bitiremediğim bir yazıydı. Anlatımda kopukluklar varsa sebebi budur, hatalarım olduysa affola.